Logging
Implémenter le Logging
Le Logging doit fournir une vue holistique du système
Notre implémentation doit tracer le flux de bout-en-bout et capturer la plus d’informations possibles.
Dans un architecture microservices nous allons avoir un service dédié pour le Logging. Les logs sont maintenant unifié, agrégé et peuvent être facilement analysés.
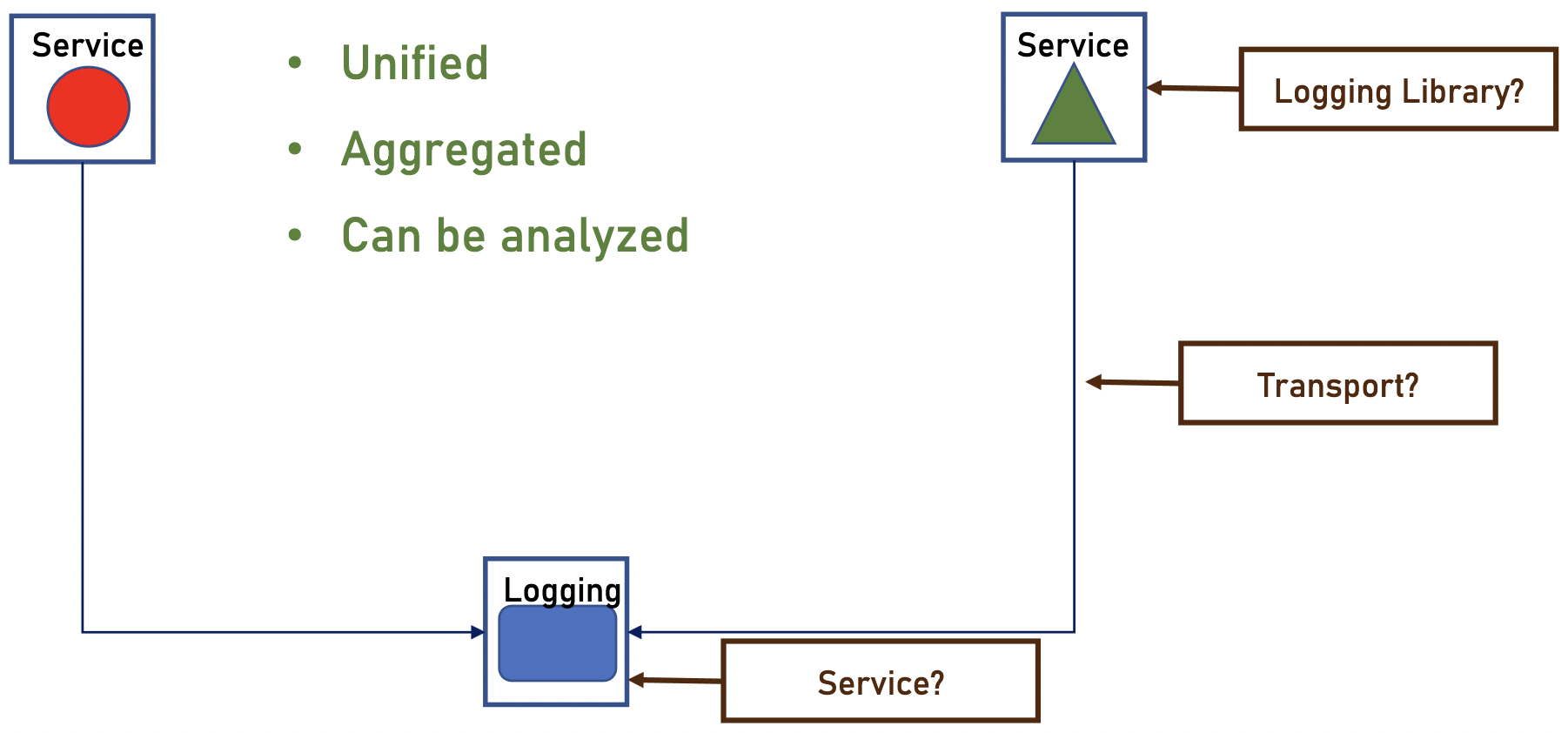
Nous devons considérer le logging à différents endroits :
- au niveau de service métier, où il nous faudra une librairie de logging pour générer les logs
- le transport, les logs doivent être transporté vers le service logging
- service logging, comment le construire ? utilise un service existant ?
Logging librairie
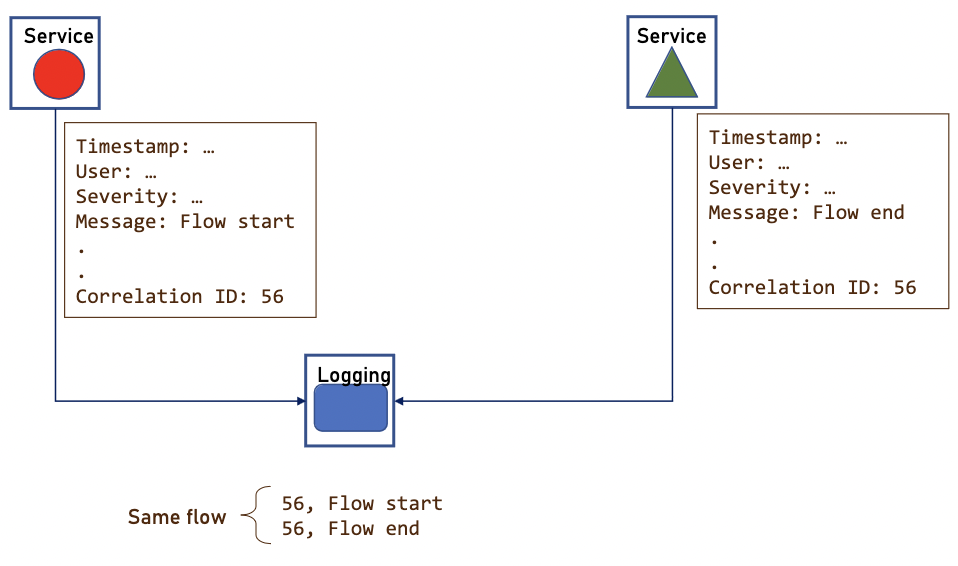
En Java Log4j est la librairie la plus populaire pour capturer les logs. Les principales informations à capturer sont les suivantes :
- La date et l’heure
- L’utilisateur
- La sévérité (INFO, WARNING, ERROR)
- Le service
- Le message
- L’ID de correlation : lorsqu’une erreur est partagé en deux services : flow start et flow end nous devons les considérer comme provenant de la même erreur. Nous pouvons donc filtrer nos erreurs en fonction du correlation id et avoir une vue globale du flux
Transport
Il faut transporter les informations du service métier vers le service de logging. La stratégie la plus utilisé est les Queues (e.g. Apache Kafka, RabbitMQ)
Logging Service
Il existe plusieurs solutions déjà existant pour tracer les logs en fournissant de bonne visualisation.
- Stack
- Splunk